Unlock peak Spark workload efficiency with real-time cost optimization
-

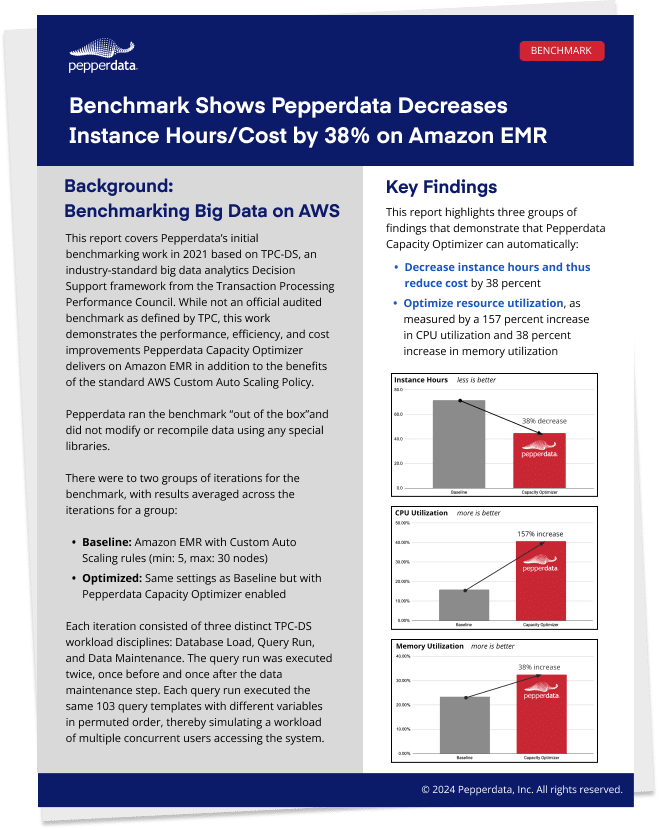
Reduced instance hours
Continuously optimize your unused node resources to reduce instance hours and costs without recommendations
-
Enhanced efficiency
Automatically utilize instances fully before adding more to gain additional savings on top of your cloud autoscaler
-
Time savings; no manual tuning
Tune your environment in real time to its “sweet spot” of optimal utilization without manual intervention
“Pepperdata allowed us to…reduce our costs by over 50%. We can focus on our business, while they optimize
for costs and performance.”—Mark Kidwell, Chief Data Architect, Data Platforms and Insights, Autodesk
![]()
Autonomously optimize your instance hour consumption in real time
Autonomously optimize your instance hour consumption in real time
Autonomously optimize your instance hour consumption in real time

Pepperdata Capacity Optimizer uses patented algorithms and machine learning to save you up to 47 percent in costs by:
- Utilizing all nodes before additional nodes are created
- Instructing the Amazon EMR scheduler to add resources to underutilized nodes so you do more at the same cost
- Launching new instances only when resource capacity in existing instances is full
Boost the efficiency of Amazon EMR
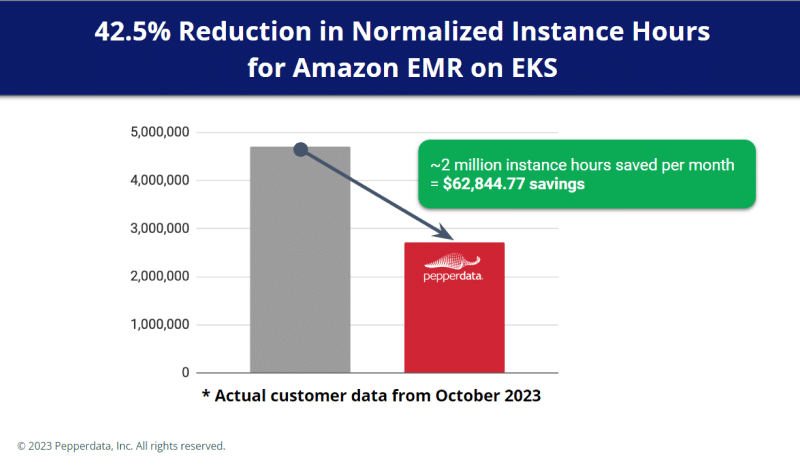
Boost the efficiency of Amazon EMR
Enterprises allocate resources for peak usage, but peak is only reached occasionally. Capacity Optimizer reduces waste by:
- Utilizing all nodes before additional nodes are created
- Working on your behalf to downscale the autoscaler in real time when fewer resources are required
- Optimizing resources automatically to eliminate manual tuning, application changes, and applying recommendations
Watch how Autodesk optimized cloud costs by over 47%
Watch how Autodesk optimized cloud costs by over 47%
Mark Kidwell, Chief Data Architect, Data Platforms and Solutions at Autodesk, highlights the results of installing Pepperdata on Amazon EMR:
- Reduced cloud costs by over 47%
- Increased resource utilization from 30% to 70%
- Doubled infrastructure efficiency