
March 14, 2026 | 5 MIN READ
Read More
Install Kubernetes Cost Optimization Quickly: How to Get Started with Pepperdata
See how easy it is to install Pepperdata in this 4-minute step-by-step video. Many organizations struggle to control their cloud costs,...


May 15, 2025 | 7 MIN READ
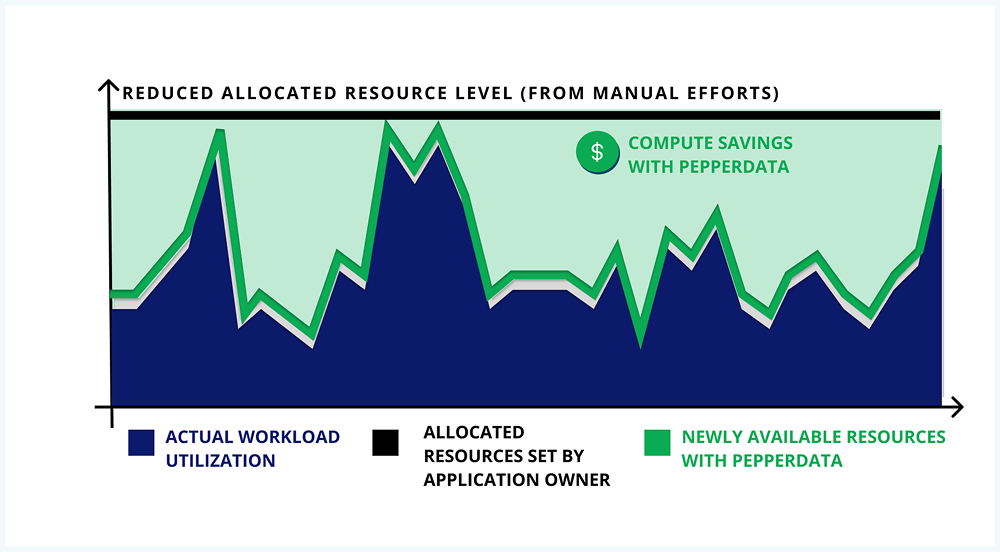
Why Manual Tuning Fails: A Better Way to Optimize Kubernetes Workloads
Read More

February 28, 2025 | 7 MIN READ
The 5 Reasons to Buy (And Not Build!) Your Cost Optimization Solution
Read More



June 27, 2025 | 6 MIN READ
