Pepperdata Capacity Optimizer for Amazon EKS
Autonomously optimize your Apache Spark cluster resources on top of Managed Autoscaling, Karpenter, Spark Dynamic Allocations, and other traditional optimization efforts such as manual tuning. Pepperdata delivers:
Autonomously optimize your Apache Spark cluster resources on top of Managed Autoscaling, Karpenter, Spark Dynamic Allocations, and other traditional optimization efforts such as manual tuning. Pepperdata delivers:
Autonomously optimize your Apache Spark cluster resources on top of Managed Autoscaling, Karpenter, Spark Dynamic Allocations, and other traditional optimization efforts such as manual tuning. Pepperdata delivers:

- Reduced instance hours and costs immediately in real-time
- Increased node utilization and reduced node quantity required to run your applications for direct cost savings
- Freedom from manual recommendations with automated, real-time optimization
If you’re running Spark, give us 6 hours, we’ll save you 30% or more on top of everything you’ve already done.
Pepperdata Reduces the Cost of Amazon EMR on EKS by 42.5%

Pepperdata Reduces the Cost of Amazon EMR on EKS by 42.5%
Running Pepperdata Capacity Optimizer alongside the autoscaler for Amazon EMR on Amazon EKS helped reduce a customer’s instance hours by 42.5%. Here are the key findings with Pepperdata:
$62,844.77
Saved in one month
~2 million
Reduced instance hours
146%
Improved normalized core efficiency
How Pepperdata enhances Karpenter at the application layer
After Karpenter deploys the right instance for your workload, Pepperdata saves a further 30% in costs by preventing Spark applications from wasting requested resources at the task level.
Here’s how Capacity Optimizer does it:
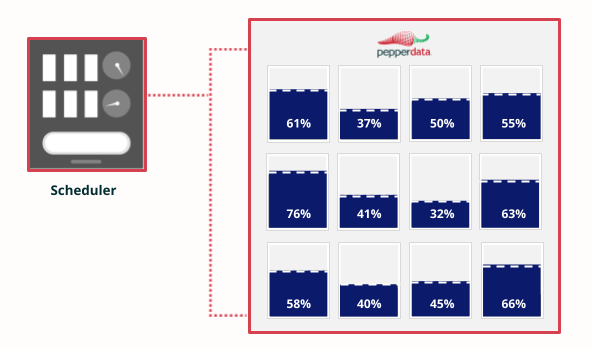
Real-time observability
Pepperdata provides the cluster scheduler with real-time data on available capacity
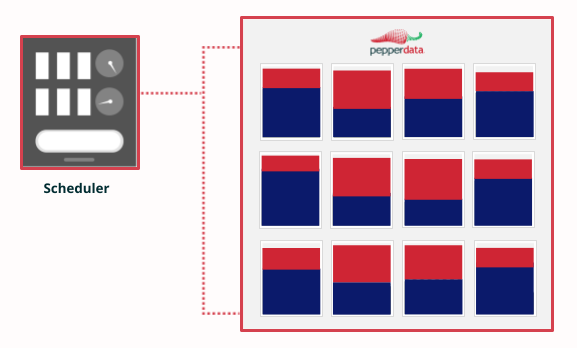
Optimized instance hours
Your scheduler adds more jobs to existing instances without spinning up new instances
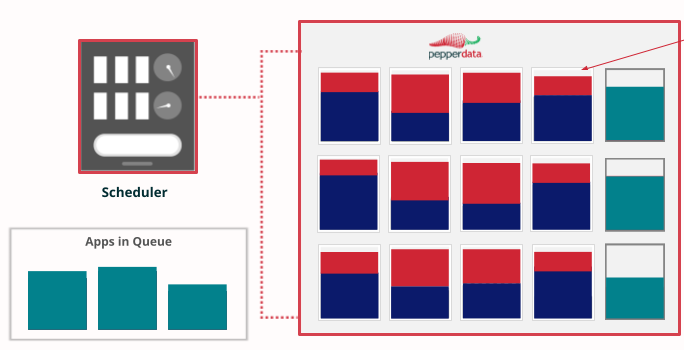
Efficient autoscaling
When new apps come along, new instances are spun up only when existing ones are truly full
Real-time observability
Pepperdata provides the cluster scheduler with real-time data on available capacity
Optimized instance hours
Your scheduler adds more jobs to existing instances without spinning up new instances
Efficient autoscaling
When new apps come along, new instances are spun up only when existing ones are truly full
Pepperdata Capacity Optimizer for Spark Workloads on Amazon EKS: Third-Party Benchmarking
41.8%
Cost Savings: Reduced instance hour consumption
45.5%
Improved Performance: Decreased application runtime
26.2%
Increased Throughput: Uplift in average concurrent container count
*TPC-DS is the Decision Support framework from the Transaction Processing Performance Council. TPC-DS is an industry-standard big data analytics benchmark. Pepperdata’s work is not an official audited benchmark as defined by TPC. TPC-DS benchmark results (Amazon EKS), 1 TB dataset, 500 nodes,
10 parallel applications with 275 executors per application.