SOLUTION BRIEFS
Pepperdata for Amazon EKS

SOLUTION BRIEFS
Pepperdata for Amazon EKS
While Kubernetes can reduce operating costs and make deployment more agile, it can also increase the complexity and cost of managing a dynamic and diverse combination of virtual machines, containers, and big data applications.
Read the Solution Brief to discover how Pepperdata reduces the cost of running Spark applications at scale on Amazon EKS by up to 41.8% and optimizes resource utilization in real time for batch workloads like Spark.
Real-Time Optimization for Spark on EKS and Amazon EMR on EKS
Apache Spark on EKS
Pepperdata Capacity Optimizer for Spark packs additional pending pods onto underutilized nodes, increasing node utilization and reducing the need for additional nodes—translating directly to reduced costs and increased performance.
Amazon EMR on EKS
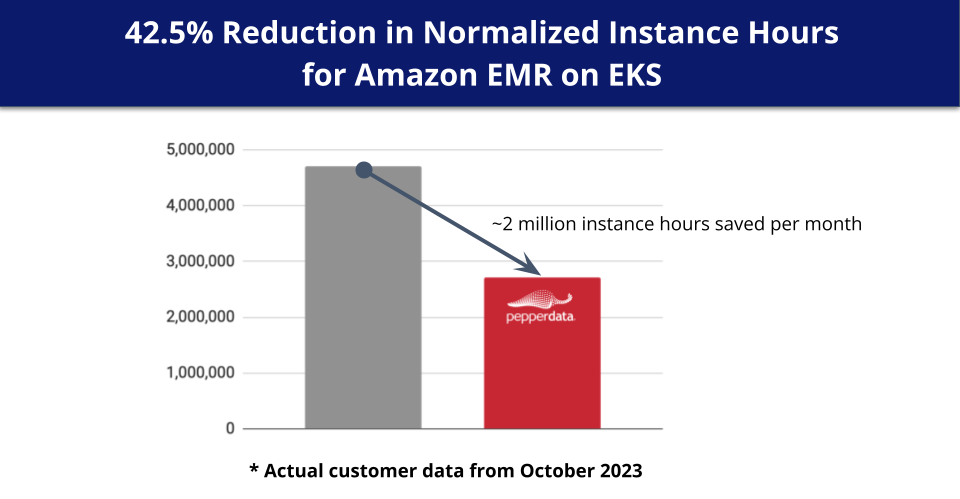
Capacity Optimizer delivers additional performance improvements and significant cost reductions for Amazon EMR workloads running on Amazon EKS by intelligently augmenting the native autoscaler to ensure all pods are fully utilized before additional pods are launched, eliminating waste and reducing costs by up to 42.5 percent.
TPC-DS Benchmarking Results
Pepperdata found that for Spark Workloads running at scale on Amazon EKS, Capacity Optimizer:
-

Reduced Cost
Decreased instance hours duration by 41.8%
-

Increased Throughput
Increased total workload run time by 45.5%
Pepperdata conducted its benchmarking using a 1 TB dataset on 500 nodes with 275 executors running on 10 parallel applications, and 99 queries TPC-DS jobs. TPC-DS is the Decision Support framework from the Transaction Processing Performance Council. The benchmark was modeled on industry standard TPC-DS big data analytics benchmark. Pepperdata’s work is an unofficial benchmark as defined by TPC.
