Extract the most from your cloud investment
Pepperdata Capacity Optimizer automatically enables your existing data-intensive workloads to run on ~30% less infrastructure.
-

Immediately reduce instance hours and cost
Only pay for what you use when CPU and memory are optimized in real time.
-

Save engineering effort with no manual tuning
Reclaim hours of engineering time that can be reallocated to GenAI and AgenticAI projects.
-

Autonomously eliminate in-application waste
without code changesAutonomously eliminate in-application waste without code changes
Data-intensive apps like Spark are extremely wasteful. Pepperdata eliminates in-app waste in real time.

Increase profit margins and competitive advantage with 30-47% average cost savings.

Run more workloads for the same cost
Re-invest savings in GenAI
Improve product and systems quality
Run more workloads for the same cost
Re-invest savings in GenAI
Improve product and systems quality
Industry examples
Customers across industries use Pepperdata Capacity Optimizer to immediately reduce cost, save time, and fuel innovation.

“Pepperdata Capacity Optimizer helps optimize the efficiency of our infrastructure to reduce our spending on servers; we also know what’s needed to achieve optimal performance for each workload.”
—Vice President, Big Data Solution Engineering, Global FinServ Customer
“Pepperdata Capacity Optimizer helps optimize the efficiency of our infrastructure to reduce our spending on servers; we also know what’s needed to achieve optimal performance for each workload.”
—Vice President, Big Data Solution Engineering, Global FinServ Customer
Real-time optimization with Continuous Intelligent Tuning
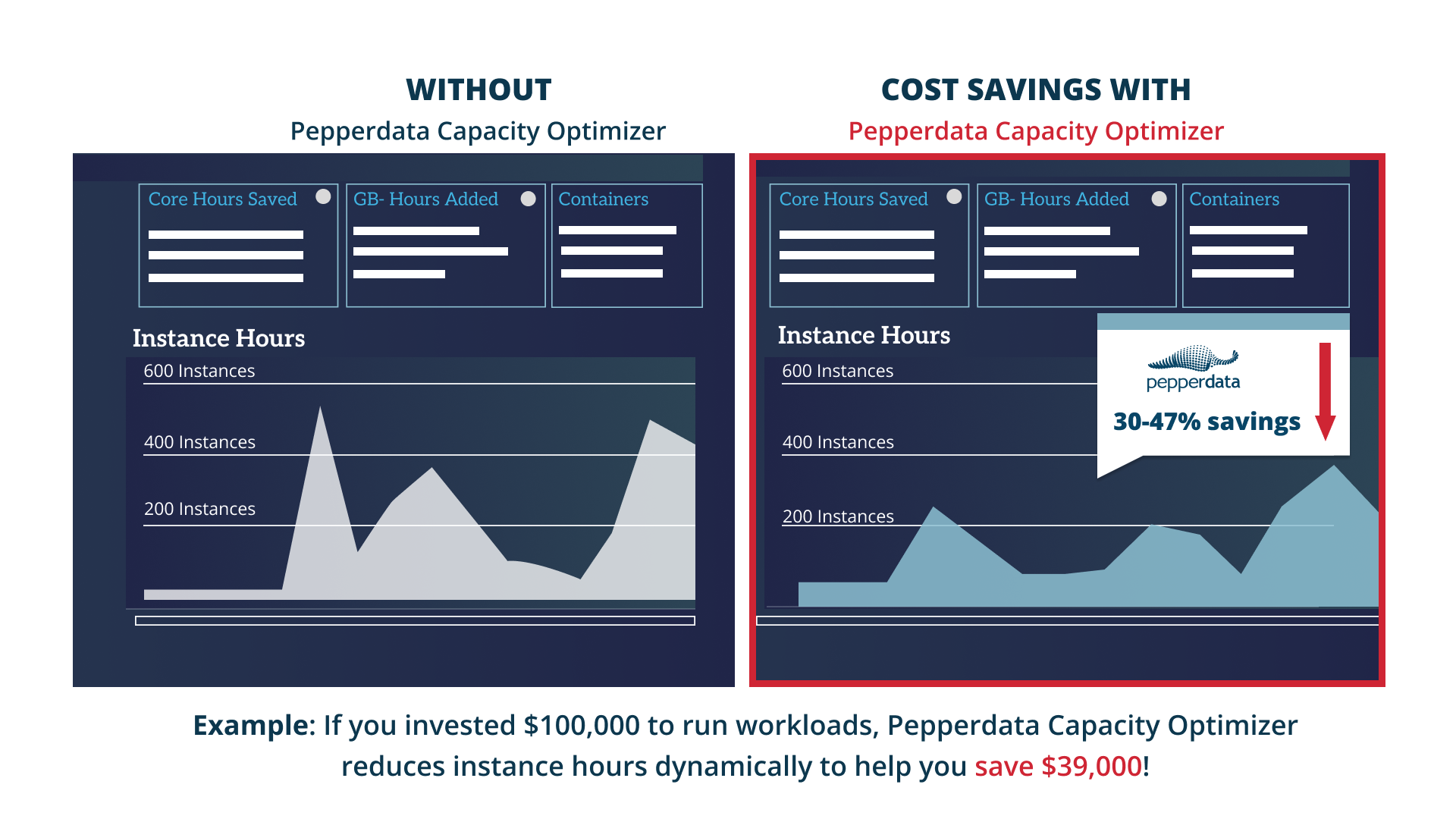
Real-time optimization with Continuous Intelligent Tuning
Pepperdata Capacity Optimizer’s Continuous Intelligent Tuning:
- Rapidly identifies unused nodes to optimize CPU and memory in real time
- Automatically adds tasks fill nodes that have available resources
- Enables new nodes to be launched only when existing nodes are fully utilized
