PRODUCT DATASHEETS
Capacity Optimizer Datasheet

PRODUCT DATASHEETS
Capacity Optimizer Datasheet
Controlling platform and application costs is incredibly difficult. Pepperdata works autonomously in real time to increase your node level utilization and reduce your application costs without any code changes.
Download the datasheet to learn how Pepperdata Capacity Optimizer’s Continuous Intelligent Tuning can save you up to 47% without needing to manually tune, apply recommendations, or make application code changes.
Key Findings
-

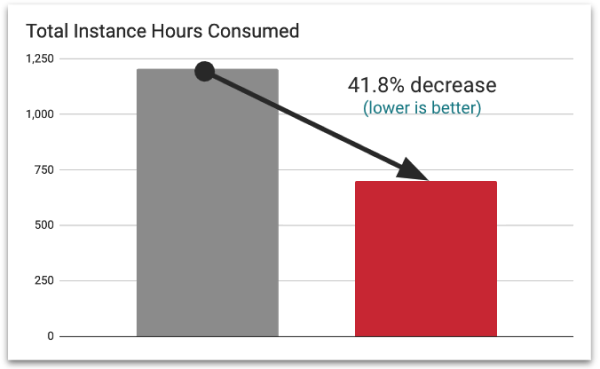
Decreased Instance Hour Consumption
for Reduced CostsCapacity Optimizer Classic reduces hardware usage by up to 47 percent by maintaining your clusters in their sweet spot of utilization.
-

No Manual Tuning, No Recommendations,
and No Application ChangesCapacity Optimizer Classic works continuously in real time and does all its work automatically, leaving no need to apply recommendations or manually tune your applications.


Achieve Significant Monthly Cost Savings on
Amazon EMR on EKS
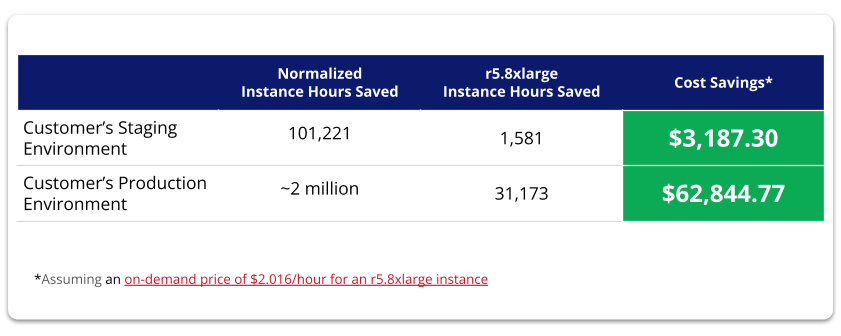
For Amazon EMR on EKS customers, Capacity Optimizer intelligently augments the native autoscaler to ensure all nodes are fully utilized before additional nodes are launched.
A Pepperdata customer recently achieved a 42.5 percent savings of instance hours and over $62K while implementing Pepperdata Capacity Optimizer on their Amazon EMR on EKS cluster.
“On average, we were saving 50% on our costs because of Pepperdata.”
—Mark Kidwell, Chief Data Architect of Data Platforms and Services, Autodesk
