Gain a complete understanding of your workloads’ resource utilization
Gain a complete understanding of your workloads’ resource utilization
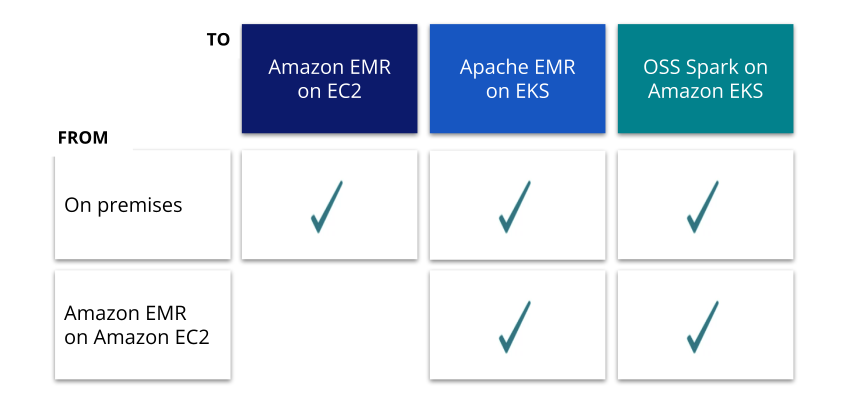
Whether you are moving on premises workloads to Amazon EMR on Amazon EC2 or moving Amazon EMR or Spark workloads onto Amazon EKS, Pepperdata empowers you to:
- Visualize your most expensive queues and users.
- Understand which instance types best suit your workloads
- Estimate your ongoing savings post-migration
Discover your waste and cost savings potential
with a Free Cloud Migration Assessment
Discover your waste and cost savings potential with a Free Cloud Migration Assessment
Discover your waste and cost savings potential with a Free Cloud Migration Assessment

-

STEP 1:
Profile your workloads via a guided install of Pepperdata: ~60 minutes
-
STEP 2:
Run Pepperdata to analyze your complete environment: ~2 weeks
-
STEP 3:
Review your customized assessment: ~60 minutes



Learn the benefits of our free Cloud Migration Assessment.
Migrate to AWS, then reduce your cloud costs
autonomously and continuously
Migrate to AWS, then reduce your cloud costs autonomously and continuously
Migrate to AWS, then reduce your cloud costs autonomously and continuously
Once you’ve migrated your on-prem workloads to the cloud, Pepperdata Capacity Optimizer minimizes wastes and maximizes efficiency to optimize your cloud costs with:
Once you’ve migrated your on-prem workloads to the cloud, Pepperdata Capacity Optimizer
minimizes wastes and maximizes efficiency to optimize your cloud costs with:
Once you’ve migrated your on-prem workloads to the cloud, Pepperdata Capacity Optimizer
minimizes wastes and maximizes efficiency to optimize your cloud costs with:
Continuous Intelligent Tuning:
Real-time, automated cost optimization for Amazon EMR and Amazon EKS with no manual tuning, no recommendations, and no application code changes.
Real-Time Resource Utilization:
Pepperdata uses Machine Learning (ML) to interact in real time with your ever-changing environment, enabling constant calibrations to keep your clusters running at the sweet spot of peak utilization without extra cost.
Augmented FinOps:
Automatically align the rigor of financial accounting with the variable cost model of the cloud so that you can maximize the value of the cloud to your business.
Schedule a Free Pepperdata Migration Assessment to get started on your cloud migration journey.
