
Reduce your cloud costs immediately without slowing down engineering
Kubernetes has revolutionized modern computing infrastructure, offering organizations near-infinite scalability, unparalleled agility in deploying new applications, and enhanced security. However, as enterprise cloud adoption continues to accelerate, that agility often comes with an unintended and costly side effect: skyrocketing cloud bills.
On average, applications use only a fraction of the allocated resources. In fact, some studies show that 27% of a cloud budget goes to waste, in part because of overallocation. Because data-intensive workloads on Kubernetes—such as Apache Spark, AI/ML pipelines, and microservices—are inherently bursty, variable, and ephemeral, continuously matching resource allocation to actual application demand is impossible to do at scale.
This guide explores why traditional optimization methods—like instance rightsizing, surface-level observability tools, and manual tuning—fail to address this fundamental problem and only serve to slow down your developers, and how implementing dynamic resource optimization can:
- Allow you to increase utilization for your clusters immediately
- Reduce cloud costs by up to 75%
- Free your engineering teams from manual tuning, applying recommendations, or changing application code
What are Traditional Solutions for Kubernetes Cost Optimization?
Organizations typically adopt a variety of strategies to minimize waste, control costs, improve efficiency, and rein in budgets at multiple levels of their infrastructure:
Business Level
- Tagging
- Cost allocation
- Chargebacks/showbacks
- Usage monitoring
Infrastructure Level in the Cloud
- Rightsizing instances
- Deploying Karpenter
- Implementing financial optimizations, such as Spot Instances, Reserved Instances and Savings Plans
Infrastructure Level On Prem
- Rightsizing hardware
- Consolidating workloads
- Purchasing refurbished servers
- Bulk discounts from vendors
Application Platform Level
- Deploying Cluster Autoscaling in cloud environments
- Migrating to a serverless architecture in cloud environments
Application Level
- Manually tuning applications and configurations
- Enabling Dynamic Resource Allocation
The solutions above are helpful across multiple layers, but true Kubernetes cost optimization shouldn't require your platform engineers to spend countless hours manually tweaking configurations or analyzing historical usage patterns. Even when spending all the time optimizing, overprovisioning will still exist due to the dynamic nature of application resource requirements.
The Fundamental Problem at the Application Level: Waste Inside the Application
Many practitioners believe that some combination of these strategies will maximize the efficiency and minimize the cost of running Kubernetes workloads. However, the fundamental problem with all of these options is that they are not able to address a specific dilemma: Kubernetes pods waste requested resources inside an application.
Waste inside the application occurs because application provisioning is static and set for peak usage throughout an application’s run, even though application resource usage actually varies dramatically over time. Even an optimally-chosen allocation level set at the peak of the application’s utilization will result in unused resources and waste since most applications typically run below peak levels most of the time.

Figure 1: Most applications run at peak provisioning levels for only a small fraction of time, resulting in waste. Even if a developer requests resources accurately for peak, the cloud autoscaler will grant the resources based on the request rather than for the actual utilization of resources required to run the application.
When developers request peak levels of resources, the Kubernetes scheduler (either the default scheduler or YuniKorn) gives them exactly what they asked for. The scheduler distributes resources based on allocation requests rather than actual usage, and has no insight into the fact that the allocated resources are not being used. As far as the scheduler is concerned, the developer asked for a certain level of resources, so that level of resources will be utilized.
To the Kubernetes Scheduler, Nodes Appear Fully Utilized

Figure 2: Within a cluster, the Kubernetes scheduler only considers the allocated resource levels, not those that are actually being used at any given time. The allocated but unused resources represent waste.
As a result, the scheduler “sees” a fully saturated cluster and interprets that as a cluster unable to accept any additional workloads.
The Kubernetes Scheduler is Unaware That Nodes Are Only Partially Utilized

Figure 3: The Kubernetes scheduler distributes resources based on allocation requests rather than actual usage, and is unaware that nodes are only partially utilized.
Then, when more applications come along in an environment that is already seen by the scheduler as fully saturated, the scheduler has only two options:
- The scheduler can put the new workloads or applications into a queue or pending state until resources free up, reducing throughput and performance.
- The scheduler can direct the autoscaler to spin up new instances at additional cost, even though existing instances are actually not fully utilized, resulting in unneeded spend for unneeded resources.
Because Nodes Appear Fully Utilized, Autoscaling Spins Up New Nodes (At Extra Cost)

Figure 4: In cloud environments, when the system appears to the scheduler to be fully saturated, the autoscaler might spin up new instances—at additional and unnecessary cost—to process them.
In either case, the result is inefficiency and waste in the system as a result of the common overprovisioning of Kubernetes pods and the inefficiencies of the scheduling system.
Why Kubernetes Costs Spiral Out of Control
How developers unintentionally overprovision resources
Most application developers request large amounts of resources to be allocated to their apps in an effort to mitigate the worst-case scenarios. What if the input data is 10x larger this time? What if the new code needs twice the memory and twice the CPU this time?
Developers often do not have the information to know exactly how much they need to allocate to handle typical worst-case scenarios. Sometimes, they don’t even know how much to allocate to handle typical scenarios.
Developers want their applications to succeed and finish in a reasonable amount of time, even in those worst-case scenarios. This desire forms the basis of their cloud cost optimization approach. That's why they ask for large allocations.
How autoscaling contributes to Kubernetes inefficiencies
Autoscaling in Kubernetes, or in any cloud environment, is essential for enterprises as it enables users to automatically add and remove instances to meet the demands of the workload. It’s an effective cloud cost optimization approach, especially for enterprises that rely on Kubernetes for their processes.
However, autoscaling in Kubernetes can result in the opposite of an enterprise’s intentions. To optimize cloud cost, cloud autoscalers add more instances when the scheduler cannot add more applications to the cluster because all the existing resources have already been allocated.
Imagine a cluster with two nodes. Let's say an application requests two nodes. The application may end up using only eight cores, but the autoscaler does not know that.
As more applications are submitted requesting more cores, the autoscaler will add more instances even though the existing instance is only 50% utilized. If new applications also use just a fraction of the allocations, the new instances will be also underutilized.
The result is many more wasteful instances and, ultimately, inflated cloud bills.
While the common strategies used to optimize Kubernetes workloads—such as manual tuning and Karpenter—provide a level of savings or optimization, none of these solve the fundamental problem of overprovisioning and waste inside pods when the application is not at peak. Resources continue to be assigned based on allocation rather than usage levels, continuing the problem of waste.
Even the most efficient infrastructure in the world—one in which every waste mitigation strategy is implemented—will then continue to run with waste since even well provisioned applications use infrastructure inefficiently. And these inefficiencies can be significant—with an estimated 27% going to waste from overprovisioning of the $419 billion spent on cloud infrastructure in 2025. Faced with these significant and often hidden costs, a modern approach is required to enhance collaboration between engineering and Finance teams, prompting FinOps to emerge as a key strategy for organizations tackling Kubernetes cost optimization challenges.
FinOps Best Practices for Cloud Cost Optimization
FinOps is a financial optimization strategy that assists businesses in minimizing cloud expenditure, maximizing cloud savings, and creating resource optimization plans by bringing greater collaboration between finance and engineering teams. It also provides visibility into cloud usage trends, costs, and opportunities for resource optimization.
Implementing FinOps best practices is essential for organizations looking to maximize the business value of their cloud and technology investments. The cloud promises agility and infinite scalability, but without a strategic framework, dynamic Kubernetes and big data workloads can quickly lead to unexpected and runaway costs. To effectively manage cloud spend, eliminate waste, and maximize ROI, organizations should adopt the following core strategies:
Align Engineering and Finance
At its core, FinOps is a cultural practice designed to break down organizational silos and bridge the gap between finance and developer operations. By fostering cross-functional collaboration, teams can align on common goals regarding speed, cost, and quality. When engineering, finance, and executive teams work together, it creates financial accountability and empowers developers to focus their brain power on product delivery and revenue-generating innovation rather than worrying about cost overruns.
Measure Utilization
You cannot optimize what you cannot accurately measure. A foundational step in any FinOps practice is ensuring that every resource consumed delivers commensurate ROI. However, native Kubernetes schedulers allocate resources based on static developer requests rather than actual physical hardware utilization. This blind spot hides massive amounts of overprovisioning waste during the valleys of an application's runtime. By gaining real-time visibility into the actual CPU, GPU, and memory utilization of your clusters, you can identify hidden capacity and accurately gauge the true efficiency of your infrastructure.
Track Cost Per Workload
Establishing clear cloud unit economics is vital for translating infrastructure metrics into business value. FinOps teams must track and attribute a monetary value against the specific costs of individual workloads and applications. Granular tracking of cost per workload allows organizations to quickly identify anomalies – such as unexpected spikes in spending due to inefficient autoscaling or overallocating CPU/memory – and take targeted action to rightsizing those specific, inefficient resources.
Forecast Spend
Accurate forecasting requires a continuous stream of data and insights. As part of the "Inform" phase of the FinOps lifecycle, gathering and analyzing critical utilization and cost data fuels strategic business decision-making. Enterprises equipped with real-time reporting and full-stack observability can accurately predict future resource needs, establish automated budget alerts, and proactively execute controls to completely eliminate the risk of overprovisioning.
Automate Optimization Efforts
While visibility and tracking are crucial, simply finding waste is not the same as fixing it. Data-intensive workloads on Kubernetes are highly bursty, variable, and ephemeral, making manual tuning and configuration tweaks practically impossible at scale. The ultimate FinOps best practice is to embrace dynamic resource optimization versus manual optimization approaches.
Solution Gaps in Manual Optimization Solutions
Here are some of the most popular manual optimization solutions and their limitations:
Visibility Tools and Cost Observability Dashboards
A variety of tools exist to allow practitioners to monitor the functionality of their cloud environments down to the individual application level. Alerts can be triggered when cloud spend or other key metrics exceed predefined thresholds.
Solution Gap:
Finding waste is not fixing waste: these tools can surface problems and generate recommendations to help you identify existing waste, but waste still needs to be eliminated manually and is difficult to achieve at scale. Recommendations translate into lengthy to-do lists, which engineering teams may have to prioritize over developing innovative applications.
Cluster Autoscaling
Cluster Autoscaling dynamically adjusts the available compute resources based on current and ever-changing workload demands, ensuring that resources are provisioned as requested.
Solution Gap:
Even with Cluster Autoscaling enabled, it’s common for Kubernetes workloads to request CPU and memory but not use them – leading to waste. Cluster Autoscaling is simply not designed to evaluate resource requests, and therefore doesn’t remediate this inherent or built-in waste inside Kubernetes pods.
Instance, Container, and Pod Rightsizing
Rightsizing refers to matching instance types and sizes to workload performance and capacity requirements at the lowest possible cost. An open-source automated tool such as Karpenter can identify opportunities to eliminate or downsize without compromising capacity or other requirements.
Solution Gap:
Although a powerful cost-saving tool, rightsizing does not completely eliminate the problem of application waste and does not address real-time changes in application performance. Overprovisioned apps will still waste money regardless of the instance type, and volatile applications can render an instance type obsolete or inappropriate over time.
Manual Tuning and Configuration Tweaks
Developers are often tapped to manually keep track of and adjust for cloud waste problems such as overprovisioning, over-scaling, and inefficient resource allocation.
Solution Gap:
Even the most experienced developers will have difficulty scaling their efforts to keep pace with the constantly changing demands of data workloads and the constant overprovisioning of these apps. Whenever an app is not running at peak, resources are being underutilized and ultimately wasted.
How Pepperdata Helps Optimize Kubernetes Costs and Resources
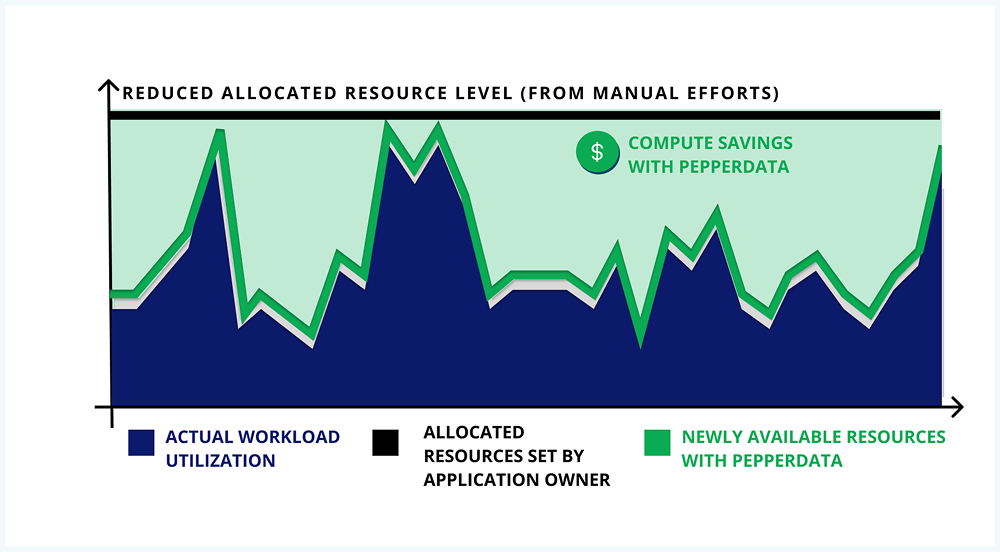
Pepperdata Capacity Optimizer remediates resource overprovisioning by providing the system scheduler with real-time visibility into actual CPU, GPU, and memory utilization levels to automatically deliver more containers per node for both Kubernetes and YARN environments.
This automatic and continuous resource rightsizing maximizes utilization levels for both the peaks and valleys of application runtime without the need for manual tuning, application code changes, or applying recommendations.
- The scheduler makes more accurate and efficient resource decisions with Pepperdata-provided real-time CPU and memory usage information.
- Workloads on nodes are launched based on real-time physical utilization.
- Pods are launched with optimized resource requests.
- The autoscaler can scale up more efficiently since nodes are packed based on actual utilization.
The results? Up to 75% in reduced costs, increased resource utilization of up to 80%, and enhanced throughput performance by continuously optimizing GPU, CPU, and memory in real time. Free your engineers from manual configuration tuning, applying recommendations, or changing application code to focus on revenue-generating innovation instead.
The Pain-Free Path to Kubernetes Cost Reduction: Get Started in Minutes
One of the biggest hurdles to cutting your cloud spend isn't knowing you have waste—it's the friction of adopting new tools. Traditional enterprise software installs can be a week-long, high-friction process involving multiple calls, handoffs, and endless configuration headaches. When finance is demanding cost reduction, you simply don't have time for a slow, complex deployment.
This is why Pepperdata built a truly self-service experience around our Kubernetes cost optimization software. The goal is simple: to put you on the fast track to identifying waste and achieving real savings with zero mandatory interaction.
The Three Core Benefits of Pepperdata's Self-Service Install
- Lightning-Fast Time-to-Value: Pepperdata's process is streamlined into a single-command bash script. Instead of waiting days for provisioning and setup, you can have the software installed, running, and collecting baseline data in under an hour.
- Unattended, Automated Installation: The script automatically handles five critical steps for you: generating a license, authenticating to registries, copying the software, adding the Helm repository, and running the install. You only need to provide your email, Amazon EKS cluster name, and Amazon ECR registry address.
- Real-Time, Quantifiable Savings: Once installed, the software works continuously and automatically to free engineers from manual tuning. Customers have seen up to 75% cost savings—and you’ll be able to track every dollar and core saved right from your dedicated dashboard.
Ready to take control of your cloud costs without the enterprise hassle?
Read the Full, Step-by-Step Installation Guide Here ➡️ Kubernetes Cost Optimization Install: The Quickest Way to Realize up to 75% Cost Savings on Kubernetes
